概述
在软件开发时,经常需要使用聚合对象来存储一系列数据。聚合对象拥有两个职责:一是存储数据,二是遍历数据。从依赖性来看,前者是聚合对象的基本职责;而后者既是可变化的,又是可分离的。因此,可以将遍历数据的行为从聚合对象中分离出来,封装在一个被称之为‘迭代器’的对象中,由迭代器来提供遍历聚合对象内部数据的行为,这将简化聚合对象的设计,更加符合单一职责原则的要求。
定义
迭代器(Iterator Pattern):提供一种方法来访问聚合对象,而不用暴露这个对象的内部表示,其别名为游标(Cursor).迭代器模式是一种对象行为型模式
结构图
在迭代器模式结构中包含聚合和迭代器两个层次结构,考虑到系统的灵活性和可扩展性,在迭代器模式中应用了工厂方法模式,其模式结构图如下
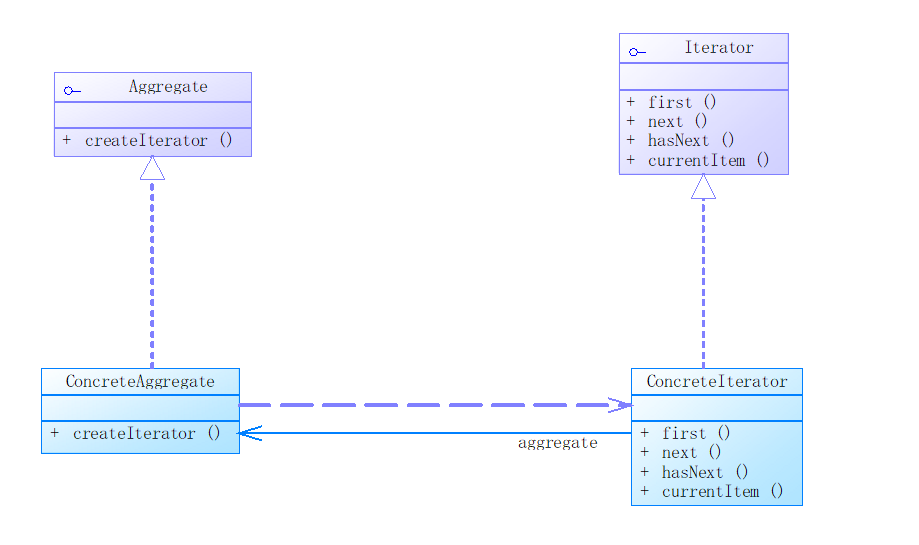
Iterator(抽象迭代器):它定义了访问和遍历元素的接口,声明了用于遍历数据元素的方法,例如,用于获取第一个元素的first()方法,用于访问下一个元素的next()方法,用于判断是否还有下一个元素的hasNext()方法,用于获取当前元素的currentItem()方法等,在具体迭代器中将实现这些方法。
ConcreteIterator(具体迭代器):它实现了抽象迭代器接口,完成对聚合对象的遍历,同时在具体迭代器中通过游标来记录在聚合对象中所处的当前位置,在具体实现时,游标通常是一个表示位置的非负整数。
Aggregate(抽象聚合类):它用于存储和管理元素对象,声明一个createIterator()方法用于创建一个迭代器对象,充当抽象迭代器工厂角色
ConcreteAggregate(具体聚合类):它实现了在抽象聚合类中声明的createIterator()方法,该方法返回一个与该具体聚合类对应的具体迭代器ConcreteIterator实例
在迭代器模式中,提供了一个外部的迭代器来对聚合对象进行访问和遍历,迭代器定义了一个访问该聚合元素的接口,并且可以跟踪当前遍历的元素,了解哪些元素已经遍历过而哪些没有。迭代器的引入,将使得对一个复杂聚合对象的操作变得简单
典型代码
在迭代器模式中应用工厂方法模式,抽象迭代器对应于抽象产品角色,具体迭代器对应于具体产品角色,抽象聚合类对应于抽象工厂角色,具体聚合类对应于具体工厂角色
在抽象迭代器中声明了用于遍历聚合对象中所存储元素的方法,典型代码如下
interface Iterator{
public void first(); //将游标指向第一个元素
public void next(); //将游标指向下一个元素
public boolean hasNext(); //判断是否存在下一个元素
public Object currentItem(); //获取游标指向的当前元素
}
在具体迭代器中将实现抽象迭代器声明的遍历数据的方法,代码如下
class ConcreteIterator implements Iterator{
private ConcreteAggregate objects; //维持一个对具体聚合对象的引用,以便于访问存储在聚合对象中的数据
private int cursor; //定义一个游标,用于记录当前访问位置
private ConcreteIterator(ConcreteAggregate objects){
this.objects = objects;
}
public void first() {
....
}
public void next(){
....
}
public boolean hasNext(){
....
}
public Object currentItem(){
....
}
}
需要注意的是,抽象迭代器接口的设计特别重要,一方面需要充分满足各种遍历操作的要求,尽量为各种遍历方法都提供声明,另一方面又不能包含太多方法,接口中方法太多将给子类的实现带来麻烦。因此可以考虑使用抽象类来设计抽象迭代器,在抽象类中为每一个方法提供一个空的默认实现。如果需要在具体迭代器中为聚合对象增加全新的遍历操作,则必须修改抽象迭代器和具体迭代器的源代码,这将违背开闭原则,因此在设计时要考虑全面,避免之后修改接口
聚合类用于存储数据并负责创建迭代器对象,最简单的抽象聚合类代码如下
interface Aggregate{
Iterator createIterator();
}
具体聚合类作为抽象聚合类的子类,一方面负责存储数据,另一方面实现了在抽象聚合类中声明的工厂方法createIterator(),用于返回一个与该具体聚合类对应的具体迭代器对象,代码如下
class ConcreteAggregate implements Aggregate{
....
public Iterator createIterator{
return new ConcreteIterator(this);
}
....
}
实例:销售管理系统的设计
结构图
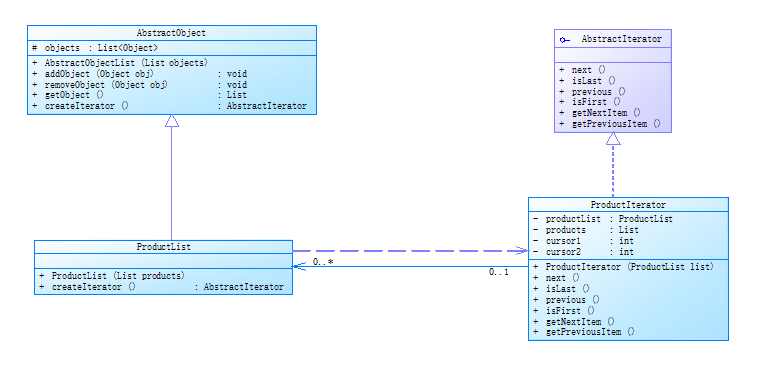
在图中,AbstractObjectList充当抽象聚合类,ProductList充当具体聚合类,AbstractIterator充当抽象迭代器,ProductIterator充当具体迭代器。
代码实现
抽象聚合类
public abstract class AbstractObjectList {
protected List<Object> objects = new ArrayList<Object>();
public AbstractObjectList(List objects) {
this.objects = objects;
}
public void addObject(Object obj) {
this.objects.add(obj);
}
public void removeObject(Object obj) {
this.objects.remove(obj);
}
public List getObjects() {
return this.objects;
}
//声明创建迭代器对象的抽象工厂方法
public abstract AbstractIterator createIterator();
}
商品数据类:具体聚合类
public class ProductList extends AbstractObjectList {
public ProductList(List objects) {
super(objects);
}
//实现创建迭代器对象的具体工厂方法
public AbstractIterator createIterator() {
return new ProductIterator(this);
}
}
抽象迭代器
public interface AbstractIterator {
public void next(); //移至第一个元素
public boolean isLast(); //判断是否是最后一个元素
public void previous(); //移至上一个元素
public boolean isFirst(); //判断是否为第一个元素
public Object getNextItem(); //获取下一个元素
public Object getPreviousItem();//获取上一个元素
}
商品迭代器:具体迭代器
public class ProductIterator implements AbstractIterator {
private ProductList productList;
private List products;
private int cursor1; //定义一个游标,用于记录正向遍历的位置
private int cursor2; //定义一个游标,用于记录反向遍历的位置
public ProductIterator(ProductList list){
this.productList = list;
this.products = list.getObjects(); //获取集合对象
cursor1 = 0; //设置正向遍历游标的初始值
cursor2 = products.size() - 1; //设置反向遍历游标的初始值
}
@Override
public void next() {
if(cursor1 < products.size()) {
cursor1++;
}
}
@Override
public boolean isLast() {
return (cursor1 == products.size());
}
@Override
public void previous() {
if(cursor2 > -1) {
cursor2 -- ;
}
}
@Override
public boolean isFirst() {
return (cursor2 == -1);
}
@Override
public Object getNextItem() {
return products.get(cursor1);
}
@Override
public Object getPreviousItem() {
return products.get(cursor2);
}
}
客户端测试
public class Client {
public static void main(String[] args) {
List products = new ArrayList();
products.add("倚天剑");
products.add("屠龙刀");
products.add("断肠草");
products.add("葵花宝典");
products.add("四十二章经");
AbstractObjectList list;
AbstractIterator iterator;
list = new ProductList(products); //创建聚合对象
iterator = list.createIterator(); //创建迭代器对象
System.out.println("正向遍历");
while(!iterator.isLast()) {
System.out.println(iterator.getNextItem() + ",");
iterator.next();
}
System.out.println();
System.out.println("-------------------");
System.out.println("逆向遍历:");
while(!iterator.isLast()) {
System.out.println( iterator.getPreviousItem() + ",");
iterator.previous();
}
}
}
如果需要增加一个新的具体聚合类,例如客户数据聚合类,并且需要为客户数据聚合类提供不同于商品数据聚合类的正向遍历和逆向遍历操作,只需增加一个新的聚合子类和一个新的具体迭代器类即可,原有类库代码无需修改,符合开闭原则;如果需要为ProductList类更换一个迭代器,只需要增加一个新的具体迭代器类作为抽象迭代器类的子类,重新实现遍历方法,原有的迭代器代码无需修改,从迭代器的角度来看,也符合开闭原则;但是如果要在迭代器中新增新的方法,则需要修改抽象迭代器源代码,这将违背开闭原则
使用内部类实现迭代器
从上图结构图中可以看出,具体迭代器类和具体聚合类之间存在双重关系,其中一个关系为关联关系,在具体迭代器中需要维持一个对具体聚合对象的引用,该关联关系的目的时访问存储在聚合对象中的数据,以便迭代器能够对这些数据进行遍历操作。
除了使用关联关系外,为了能够让迭代器可以访问到聚合对象中的数据,还可以将迭代器类设计为聚合类的内部类,JDK中的迭代器类就是通过这种方法来实现的,其中AbstractList类代码片段如下:
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
.....
private class Itr implements Iterator<E>{
int cursor = 0;
....
}
.....
}
可以通过类似的方法来设计ProductList类,将ProductIterator类作为ProductList类的内部类,代码如下:
public class ProductList extends AbstractObjectList {
public ProductList(List objects) {
super(objects);
}
//实现创建迭代器对象的具体工厂方法
public AbstractIterator createIterator() {
return new ProductIterator();
}
//商品迭代器:具体迭代器,内部类实现
public class ProductIterator implements AbstractIterator {
private int cursor1; //定义一个游标,用于记录正向遍历的位置
private int cursor2; //定义一个游标,用于记录反向遍历的位置
public ProductIterator(){
cursor1 = 0; //设置正向遍历游标的初始值
cursor2 = objects.size() - 1; //设置反向遍历游标的初始值
}
@Override
public void next() {
if(cursor1 < objects.size()) {
cursor1++;
}
}
@Override
public boolean isLast() {
return (cursor1 == objects.size());
}
@Override
public void previous() {
if(cursor2 > -1) {
cursor2 -- ;
}
}
@Override
public boolean isFirst() {
return (cursor2 == -1);
}
@Override
public Object getNextItem() {
return objects.get(cursor1);
}
@Override
public Object getPreviousItem() {
return objects.get(cursor2);
}
}
}
无论使用哪种实现机制,客户端代码都是一样的,也就是说客户端无需关心具体迭代器对象的创建细节,只需要通过调用工厂方法createIterator()即可得到一个可用的迭代器对象,也就是使用工厂方法模式的好处,通过工厂来封装对象的创建过程,简化了客户端的调用。
JDK内置迭代器
在java集合框架中,常用的List和Set等聚合类的子类都间接实现java.util.Collection接口,在Collection接口中声明了如下方法(部分):
public interface Collection<E> extends Iterate<E>{
....
boolean add(Object c);
boolean addAll(Collection c);
boolean remove(Object c);
boolean removeAll(Collection c);
Iterator iterator();
....
}
除了包含一些增加元素和删除元素的方法外,还提供了一个iterator()方法,用于返回一个Iterator迭代器对象,以便遍历聚合中的元素;具体的java聚合类可以通过实现该iterator()方法返回一个具体的Iterator对象。
JDK中定义了抽象迭代器接口Iterator,代码如下
public interface Iterator<E>{
boolean hasNext();
E next();
void remove();
}
其中,hasNext()用于判断聚合对象中是否还存在下一个元素,为了不抛出异常,在每一次调用next()之前需要先调用hasNext(),如果有可供访问的元素,则返回true;next()方法用于将游标移至下一个元素,通过它可以逐个访问聚合中的元素,它返回游标所越过的那个元素引用;remove()方法用于删除上一次调用next()时所返回的元素。
用于删除聚合对象中的第一个元素的代码片段如下
Iterator iterator = collection.iterator(); //collection 是已实例化的聚合对象
iterator.next(); //跳过第一个元素
iterator.remove(); //删除第一个元素
需要注意的是,在这里next()方法与remove()方法的调用是相互关联的。如果调用remove()之前没有先对next()进行调用,那么将会抛出一个IllegalStateException异常,因为没有任何可供删除的元素.
用于删除两个相邻元素的代码片段如下
iterator.remove();
iterator.next(); //如果删除此行代码,程序将抛出异常
iterator.remove();
在上面的代码片段中,如果将代码'iterator.next()'去掉则程序运行抛出异常,因为第二次删除找不到可供删除元素。
在JDK中,Collection接口和Iterator接口充当了迭代器模式的抽象层,分别对应于抽象聚合类和抽象迭代器,而Collection接口的子类充当了具体聚合类,下面以List为例加以说明,如下图列出JDK中部分与List有关的类与它们之间的关系
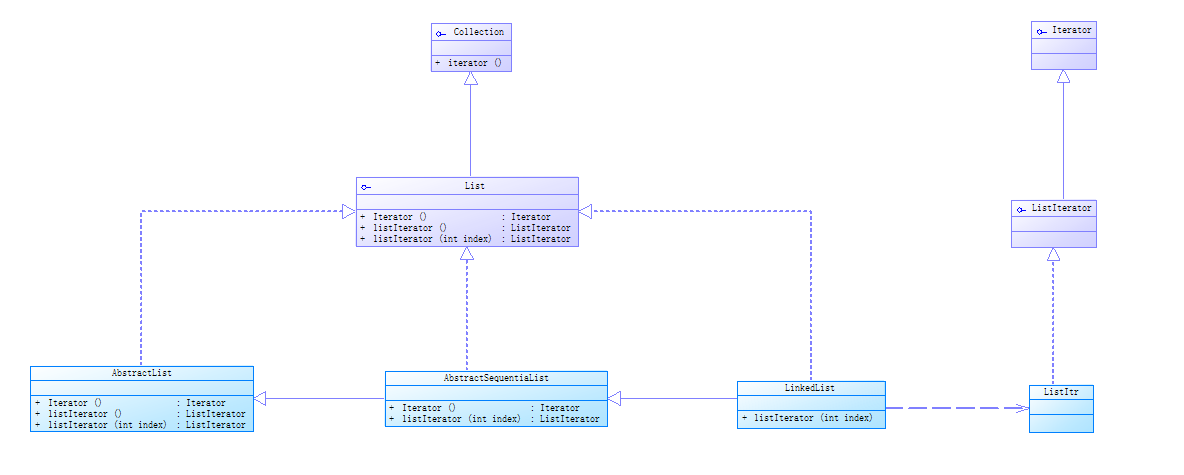
在JDK中,实际情况比上图要复杂,在图中List接口除了继承Collection接口的iterator()接口外,还增加了新的工厂方法listIterator(),专门用于创建ListIterator类型的迭代器,在List的子类LinkedList中实现了该方法,可用于创建具体的ListIterator子类ListItr的对象,代码如下:
public ListIterator<E> listIterator(int index){
return new ListItr(index);
}
listIterator()方法用于返回具体迭代器ListItr类型的对象,在JDK源代码中,AbstractList中的iterator()方法调用了listIterator()方法,代码如下:
public Iterator<E> iterator(){
return listIterator();
}
客户端通过调用LinkedList类的iterator()方法,即可得到一个专门用于遍历LinkedList的迭代器对象。
JDK中既然有了iterator()方法,为什么还要提供一个listIterator()方法呢? 由于在Iterator接口中定义的方法太少了,只有3个,通过这三个方法,只能实现正向遍历,但有时候需要对一个聚合对象进行逆向遍历等操作,因此在JDK的ListIterator接口中声明了用于逆向遍历的hasPrevious()和previous()等方法,所以当客户端需要实现逆向遍历时,只能通过以下代码创建ListIterator类型的迭代器对象:
ListIterator i = c.listIterator();
总结
迭代器模式是一种使用频率非常高的设计模式,通过引入迭代器数据可以将数据的遍历功能从聚合对象中分离出来,聚合对象只负责存储数据,而遍历数据由迭代器来完成,由于很多编程语言的类库都已经实现了迭代器模式,只需要直接使用java等语言定义好的迭代器即可。
优点
支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式,在迭代器模式中只需要用一个不同的迭代器来替代原有迭代器即可改变遍历算法,也可以自己定义迭代器的子类支持新的遍历方式。
迭代器简化了聚合类。由于引入迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
在迭代器模式中,由于引入抽象层,增加新的聚合类和迭代器类都很方便,无需修改原有代码,满足开闭原则
缺点
由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性
抽象迭代器的设计难度较大,需要充分考虑到系统将来的扩展,例如JDK内置迭代器Iterator就无法实现逆向遍历,如果需要实现逆向遍历,只能通过其子类ListIterator等来实现,而ListIterator迭代器无法用于操作Set类型的聚合对象。在自定义迭代器时,创建一个考虑全面的抽象迭代器并不是一件很容易的事情。
适用场景
访问一个聚合对象的内容无须暴露它的内部表示。将聚合对象的访问与内部数据的存储分离,使得访问聚合对象时无须了解其内部实现细节
需要为一个聚合对象提供多种遍历方式。
为遍历不同的聚合结构提供一个统一的接口,在该接口的实现类中为不同的聚合结构提供不同的遍历方式,而客户端可以一致性地操作该接口